TSQL Execution Plan Operator - Adaptive Join
The adaptive join was introduced in Azure SQL Database and in SQL Server 2017. It’s a new join type that can enable the choice of a Hash Join or Nested Loops join method at runtime until after the first input has been scanned. In this video, we’ll be going to learn about how this adaptive join operator works and will also see some of the dependencies to use this join.
In this session, we’ll be going to learn about the next physical operator of the T-SQL execution plan called an Adaptive join. The Adaptive join was introduced in the Azure SQL database and in SQL server 2017. It is a new join type that can enable the choice of a Hash join or Nested Loop join method at runtime until after the first input has been scanned.
A query plan can dynamically switch to a better join strategy during execution time to decide when to switch to a Nested Loop join or a Hash join based on the threshold defined in it. As a query is executed and it is determined that it has either met the threshold level or exceeded it.
The processing continues down the correct branch of the Adaptive join. The way it works is that it starts out building an adaptive buffer of join input. If the join input exceeds a specific row count threshold, then your plan continues with a Hash join. If the row count of the join input is small enough of threshold that is Nested Loop join would be more optimal than a Hash join. Then the plan switches to a Nested Loop join. One thing to note is the Adaptive join is applicable only to Columnstore index scan, which is used to provide rows for the Hash join build phase.
Now before executing this query, first I need to create a non clustered index on the Sales Order Header table. As I said earlier, it is mandatory to create a Columnstore index to use the Adaptive join. Create the Columnstore index.
Before we go ahead, this is the same query that we have used in the earlier demo session. The only difference in this demo is the change in the WHERE clause. In the WHERE clause, I have specified a Territory ID =1.
SELECT header.customerID, header.OrderDate, detail.ProductID, detail.UnitPrice, detail.CarrierTrackingNumber FROM sales.SalesOrderHeader AS header INNER JOIN sales.SalesOrderDetail detail ON header.SalesOrderID = detail.SalesOrderID WHERE header.TerritoryID = 1 GO
Now execute the query and check the execution plan of this query. We can see that our query is using a new Adaptive join operator. This Adaptive join operator uses a threshold that is used to decide when to switch to a Nested Loop join or a Hash join plan.
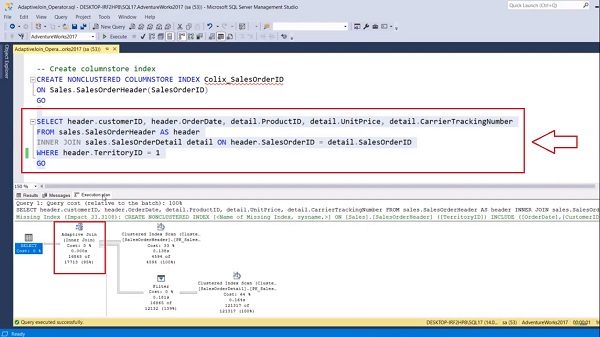
In this example, when I hover over this Adaptive join operator, you can see the threshold row count is 1074. It means anything with greater than or equal to 1074 rows will use a Hash join. The less than the threshold row count, then a Nested Loop join will be used. In our case, this query is returning the 16,865 rows. It means this exceeded the threshold row count limit and hence we have a standard Hash join operation. Now modify the WHERE clause. Over here, instead of Territory ID, add the Customer ID.
SELECT header.customerID, header.OrderDate, detail.ProductID, detail.UnitPrice, detail.CarrierTrackingNumber FROM sales.SalesOrderHeader AS header INNER JOIN sales.SalesOrderDetail detail ON header.SalesOrderID = detail.SalesOrderID WHERE header.CustomerID = 29565 GO
Now execute the query again and in the execution plan tab, when I hover over the Adaptive join operator, you can see that the adaptive threshold row count is 391. But our query is returning only 10 rows which is less than the threshold row count.
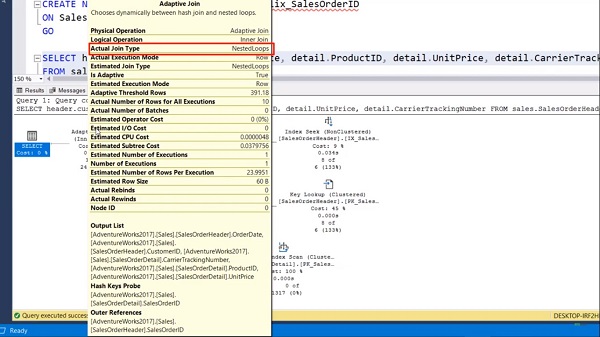
It means we have a Nested Loop join operation which we can see in the adaptive join type. Technically this Adaptive join does not represent a new type of join, but the behavior of dynamically switching between the two core types which are Nested loop and Hash match makes this effectively a new join type.
For more videos and articles visit:
Useful Links:
👉 GET YOUR FREE API KEY for PDF.co
https://app.pdf.co/signup?utm_source=youtube
✅ ON-PREMISE SDK FREE TRIAL:
https://bytescout.com/download/web-installer?utm_source=youtube
🔎 SDK DOCUMENTATION:
https://bytescout.com/documentation/