TSQL Execution Plan Operator - Lookup
In SQL Server Lookup operator manifests in a couple of different forms. The first is the key lookup operator which formerly known as bookmark lookups which are a mechanism to navigate from a nonclustered index row to the corresponding data row in the clustered index and it’s always through a nested loop operation.
A key lookup occurs when data is found in a non-clustered index, but additional data is needed from the clustered index to satisfy the query and therefore a lookup occurs and another form of lookup is RID lookup. This RID lookup is associated with a bookmark lookup to a heap. In this video, we’ll be going to learn about these two operators.
In this session, we’ll be going to learn about one of the T-SQL execution plan operator lookup. To maximize the benefit from the non clustered indexes, you must minimize the cost of the data retrieval as much as possible. A major overhead associated with the non clustered indexes is the cost of excessive lookups.
Lookup operators manifest in a couple of different forms. The first is the key Lookup operator formerly known as Bookmark Lookup which is a mechanism to navigate from a non clustered index row to the corresponding data row in the clustered index. It’s always through a nested loop operation.
A key lookup occurs when data is found in a nonclustered index but additional data is needed from the cluster index to satisfy the query. Therefore a lookup occurs and we can avoid them with a covering index. We will see this in the upcoming demo and then another form of lookup is RID Lookup. The RID lookup is associated with a bookmark lookup to a heap. So when your table doesn’t have a clustered index, the optimizer uses RID lookup instead of Key Lookup using the cluster index.

For the demo purpose here, I’m using an adventure work database and the first thing I want to do is to execute this query.
SELECT BusinessEntityID, FirstName, LastName, PersonType From Person.Person WHERE LastName = ‘Russell’ GO
In this query, we are accessing data where the last name is equal to ‘Russell’ and in my select close, I have a business entity ID, the first name, last name, and person type. Now, before executing this query, let me enable the execution plan. After execution if we look at the execution plan, we have an index seek using this index. We also have a key lookup operator on the cluster index of the person table. We also have a nested loop operator right here.
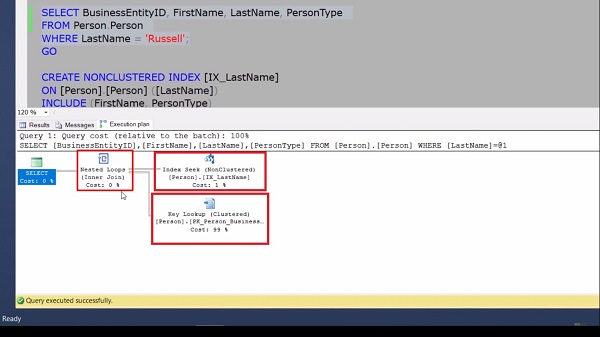
The reason why we have that lookup is because this particular [IX_LastName] even though it’s been used to traverse the B tree and get the qualifying rows. But it doesn’t have all the columns that we need for the final result, such as first name, person type, and so on. To get rid of this lookup, we need to make the existing index into a covering index. There are pros and cons in doing this, but in this scenario, if we want to cover the query entirely, we can recreate the non-cluster index.
CREATE NONCLUSTERED INDEX [IX_LastName] ON [Person].Person INCLUDE (FirstName, PersonType) WITH (DROP_EXISTING = ON) GO
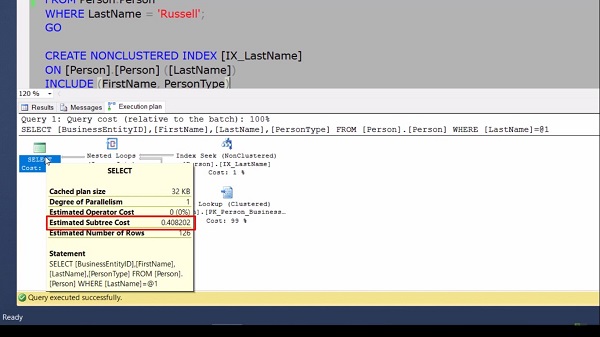
In our case, in this index, I have added first name and person type in the include section. Now before executing this nonclustered index, one thing we need to note here is the estimated subtree cost of the entire select statement. When I hover over this operator, we can see our estimated subtree cost is 0.408202 (zero point four zero eight two zero two).
Let’s go ahead and recreate this index with a covering column. Now execute the same query again. When I go to the execution plan, here we can see that we no longer have a key lookup. We also no longer have the nested loop operator. It is using our updated index [IX_LastName].
Because this index has everything that it needs. It has the key column and it has the lookup column in the leaf level. Now, once again, let’s take a look at the estimated subtree cost. This time you can see that it is 0.0034206 (zero point zero three four two zero six) which is very lesser compared to the previous subtree cost.
For more videos and articles visit:
Useful Links:
👉 GET YOUR FREE API KEY for PDF.co
https://app.pdf.co/signup?utm_source=youtube
✅ ON-PREMISE SDK FREE TRIAL:
https://bytescout.com/download/web-installer?utm_source=youtube
🔎 SDK DOCUMENTATION:
https://bytescout.com/documentation/