TSQL Execution Plan Operator - Hash Match Join
A Hash match join is generally used when your input tables have a good amount of rows and no proper indexes exist on them. So basically a hash join builds a hash table by computing a hash value for each row from its build input.
The general form of hash join is the in-memory hash join, in which the entire outer build table is scanned and computed the hash key for each row, and then a hash table is a built-in memory. In this video, we’ll be going to learn about how this hash join operator works.
In this session, we’ll be going to learn about the next physical operator of the T-SQL execution plan called a Hash Join. It is generally used when your input tables have a good amount of rows and no proper indexes exist on them. Basically, a Hash Join builds a hash table by computing a hash value for each row from its build input.
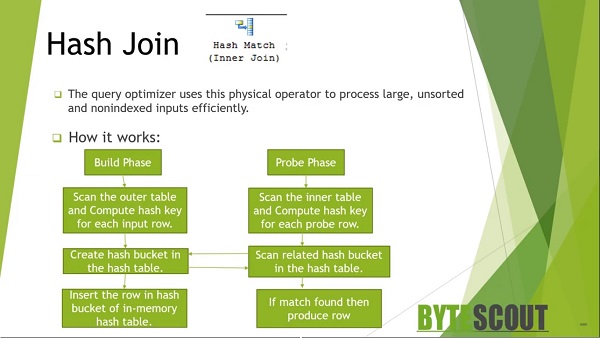
The Hash Join performs its operation in two phases which are the Build Phase and the Probe phase. The general form of Hash Join is the in-memory hash join in which the entire outer build table is scanned and computed the hash key for each row. Then a hash table is a built-in memory.
Each row from the outer input is inserted into a hash bucket, depending on the hash value computed for the hash key. This Build Phase is followed by a Probe Phase. In the Probe Phase, the entire probe input is scanned and computed one row at a time. Each probe row a hash key value is computed and the corresponding hash bucket is scanned for the hash key value from the probe input. Then the matches are produced. A hash function requires a significant amount of CPUs to generate hashes and memory resources to store the hash table.
As I earlier said, a Hash Join uses the two join input which is Build input and Probe input. Now, before we execute this query,
–Hash Join Operator SELECT product.Name, category.Name ASProductCategory FROM Production.Product INNER JOIN Production.ProductCategory AS category ON product.ProductSubcategoryID = category.ProductCategoryID
GO
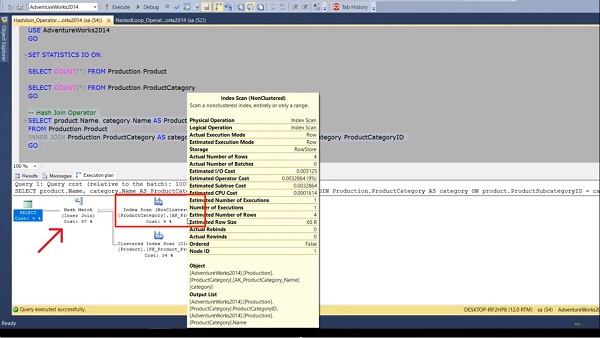
check the count in each table. After executing the query, we see that the product table has 504 rows and the product category table has 04 rows. Usually, the smaller of the two inputs serve as the build input. That means the product category table will work as a built input table and the product table which has 504 rows is working as a probe input.
Now in this query, I’m fetching product name and category name by joining these two tables on product category ID. Now execute the query and go to the execution plan tab. Here, we can see that our query is using a Hash Match Join between the two tables. The build input table is represented by the top outer table in the execution plan. In our case, it is the product category table. The probe input is the bottom table in the execution plan which is the product table.
Open the query which we have used in the Nested Loop operator demo. So I have copied this query
SELECT header.customerID, header.OrderDate, detail.ProductID, detail.UnitPrice, detail.CarrierTrackingNumber
FROM sales.SalesOrderHeader AS header INNER HASH JOIN sales.SalesOrderDetail detail ON header.SalesOrderID = detail.SalesOrderID WHERE header.CustomerID = 29565 GO
from the top one. Now in this query try to forcefully use a Hash Join between these two tables by adding a hash keyword.
When I run these three queries together and check the execution plan here, we can see that the overall cost relative to the batch of the hash join is quite high 55% in comparison with the merge join which is 44%. SQL optimizer does really a great job in deciding which join operator to use in which condition. This is just for our knowledge. It is not recommended to use join hints to force SQL Server to use a specific join operator.
For more videos and articles visit:
Useful Links:
👉 GET YOUR FREE API KEY for PDF.co
https://app.pdf.co/signup?utm_source=youtube
✅ ON-PREMISE SDK FREE TRIAL:
https://bytescout.com/download/web-installer?utm_source=youtube
🔎 SDK DOCUMENTATION:
https://bytescout.com/documentation/